

|
Like so many of my proofreading and editing colleagues, I never rely on my eye alone. I’m human, and my eye sometimes sees what it wants to see rather than what’s there, even when I’m working with clients rather than reading for pleasure.

TextSTAT: Creating a frequency list
One of my favourite tools is TextSTAT. Actually, it wasn’t created with the proofreader or editor in mind. Rather, the program was designed to enable users to analyse texts for word frequency and concordance. However, I use it to generate, very quickly, simple alphabetized word lists.
Time and again, those word lists have flagged up potential problems that I need to check in a proofreading or copyediting project. If I'm proofreading a PDF, I strip the text from the PDF proof and dump it into a Word file. I remove word breaks from that Word file (using "-^p") so that TextSTAT generates a list of whole words that I can compare, rather than thousands of useless broken words). If I'm editing in Word, I can obviously bypass the above steps. Identifying potential problems in text
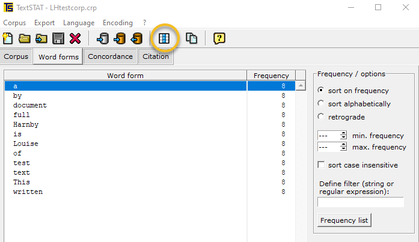
Here’s a small sample from a word list I generated in TextSTAT. As you can see, there are several possible problems:
(The colour coding is mine; I've provided it for clarity only. TextSTAT's word lists are in plain text.)
Upon checking the actual proofs, some of these issues turned out to be fine. For example:
Some issues had to be queried. For example:
Some issues needed further checking and amending. For example:
When proofreading hard-copy or PDF proofs, would I have spotted these problems with my eye alone? I'm not confident I'd have got everything, particularly the issues with the names of the less well-known cited authors. And if "beginings" had been in point-9 italic text, my eye might have passed over the missing letter. Where’s the context?
There is no context – that’s the point. When using TextSTAT as a word-list generation tool, we’re just looking at one word and how it compares with words above and below it in our list.
We’re not reading phrases; we’re not paying attention to grammar and syntax. It’s just a long list of words in alphabetical order. Later, we can focus on the words in context – TextSTAT’s word lists are just a tiny part of a process that help the proofreader or editor to provide his or her client with a polished piece of work. Fast, free and offline
TextSTAT isn’t the only word-list generation tool available for free. However, I love it because it can handle huge chunks of text without glitching – it will quickly generate word lists for books with hundreds of thousands of words (the sample I gave above was taken from a project of over 150,000 words, but I’ve used the program for larger projects). It’s never crashed on me.
You can download the software to your own computer, so there’s no issue regarding confidentiality. My clients don’t want me to upload their content to third-party browsers without their permission, so when I use a particular proofreading tool to augment my eye, that tool needs to be able to sit offline on my PC. Furthermore, it costs nothing. Say the creators: “TextSTAT is free software. It may be used free of charge and it may be freely distributed provided the copyright and the contents of all files, including TextSTAT.zip itself, are unmodified. Commercial distribution of the programme is only allowed with permission of the author. Use TextSTAT at your own risk; the author accepts no responsibility whatsoever. The sourcecode version comes with its own license." Is it worth the effort?
Some might think that an hour or so trawling through a simple word list, and cross-checking any potential problems against hard copy or PDF, is a lot of extra time to build into a proofreading project. I think that time improves the quality of my work and increases my productivity.
When I come to the actual reading-in-context stage, I'm confident that some really serious snags have already been attended to. That gives me peace of mind and enables me later to focus on other important issues like the page layout, the sense of the text, and more. I've found that using this method for dense academic projects has been particularly worthwhile. However, I'll not forget a recent fiction project (a "big name"-authored book that's in its nth edition and was first published over two decades ago) where the main protagonist's name was spelled incorrectly in two places: an easy thing to miss again and again over many years and many proofreads. I caught it – not because my eyes are better than those who came before me, or because I'm a better proofreader than those who came before me, but because I used a simple tool that allowed me to concentrate on just the words. Want to try TextSTAT?
If you want to give it a spin, it’s available from NEON - NEDERLANDS ONLINE.
The usual caveat applies: generating word lists as part of the proofreading and editing process isn't the one and only true way. TextSTAT is an example of one tool that I and some of my colleagues utilize to improve the quality of our work. You might utilize different tools and different methods to achieve the same ends. All of which is great! How to use TextStAT
These instructions are correct as of 24 June 2021.

Louise Harnby is a line editor, copyeditor and proofreader who specializes in working with crime, mystery, suspense and thriller writers.
She is an Advanced Professional Member of the Chartered Institute of Editing and Proofreading (CIEP), a member of ACES, a Partner Member of The Alliance of Independent Authors (ALLi), and co-hosts The Editing Podcast.
7 Comments
Denise Cowle
29/9/2014 01:06:48 pm
Thanks, Louise, I hadn't heard of this tool - it sounds very useful. I imagine it would help with large numbers of Arabic names which can have several variations of capitalisation, hyphenation and spelling. I think I'll try it on an upcoming job!
Helen Hull
2/7/2020 12:13:38 pm
Hi Denise, Surely PerfectIt would catch all word variants, I'm thinking...hoping (as I've just bought it!)?
Louise Harnby
2/7/2020 12:32:58 pm
Hi, Helen.
Scott B.
29/9/2014 04:19:14 pm
Thanks for mentioning this tool. I've been using it for years. I always run it at the beginning of a project on a set of documents to catch all of the inconsistencies, misspellings, and other issues. I then use an internal tool to find and replace across multiple documents. 22/8/2018 08:21:30 am
Hi Louise. I'd never heard of this tool either so was interested to read this post. If a proofreader was already running PerfectIt and Paul Beverley's macro ProperNounAlyse, do you think TextSTAT would still be a useful addition? Thank you as always!
Louise Harnby
22/8/2018 06:40:23 pm
Hi, Nancy! Yes, I think it could be a good addition. It focuses on all words (though that means the list is huge), not just proper nouns. At least try it. I spot the odd typo too. It wasn't designed to be used in this way so you might find it too cumbersome but I think it's worth having a play with at the very least! Leave a Reply. |
PDF MARKUP
AUTHOR RESOURCES
EDITOR RESOURCES
TESTIMONIALSDare Rogers'Louise uses her expertise to hone a story until it's razor sharp, while still allowing the author’s voice to remain dominant.'Jeff Carson'I wholeheartedly recommend her services ... Just don’t hire her when I need her.'J B Turner'Sincere thanks for a beautiful and elegant piece of work. First class.'Ayshe Gemedzhy'What makes her stand out and shine is her ability to immerse herself in your story.'Salt Publishing'A million thanks – your mark-up is perfect, as always.'CATEGORIES
All
ARCHIVES
July 2024
|











 RSS Feed
RSS Feed
|
|
|
|

|

|
|
|
|

© 2011–2024 Louise Harnby